
Aprendendo a ler: processamento de linguagem natural e machine learning para o processamento de dados textuais
A gente vive aprendendo das mais variadas formas. Aprendemos lendo, vendo, ouvindo ou com experiências. Os estímulos capturados pelos nossos sentidos geram dados que são incorporados ao que já sabemos para gerar um novo conhecimento ou reforçar os existentes. A fonte dessas informações, muitas vezes são imagens e textos. Mas e uma máquina? É possível fazer uma máquina aprender? É possível uma máquina entender imagens e textos? Ou melhor, será que podemos fazer uma máquina aprender a ler?
Como nós aprendemos
O vídeo a seguir mostra vários momentos nos quais aprendemos. O ser humano tem a capacidade de aprender de diversas maneiras e muitas delas estimuladas por experiências e observação.
Segundo esse texto,
Your child learns best by actively engaging with her environment. This includes: observing things, watching faces and responding to voices, listening to sounds, making sounds and singing, exploring – for example, putting things in her mouth, shaking things and turning things around, asking questions – for example, ‘But why?’, experimenting with textures, objects and materials like water, sand or dirt, doing things that stimulate all of her senses – touch, taste, smell, vision and hearing.
Fonte: https://raisingchildren.net.au/babies/play-learning/learning-ideas/learning-baby-to-preschool
Your child also learns by being involved in his learning. This could be as simple as: choosing books to read, pointing to pictures in books, choosing objects and toys to play with, picking out vegetables for dinner, measuring out flour for muffins.
Ou seja, precisamos de um ambiente que nos estimule a aprender a partir de imagens, sons, textos. Isso vem através dos brinquedos, dos livros e da troca de experiência entre adultos e crianças.
Mas, o que isso tem haver com computação?
A minha discussão parte de uma frase dita por Tom Mitchell, pesquisador na área de processamento de linguagem natural.
If we wish to predict the future of machine learning, all we need to is identify ways in which people learn but computers don’t, yet.
Tom Mitchell em Conversation Machine Learning Talk, 2018
Ou seja, se quisermos de fato fazer com que as máquinas aprendam devemos olhar como nós aprendemos. E como disse, nós aprendemos de diversas maneiras. Talvez uma das que mais utilizamos são os textos e as imagens. E acredito que o caminho seja por aí.
Digo isso pelo simples fatos: nós nunca geramos tantas imagens e textos. Basta dar uma olhada na internet e ver o quanto de informação deste tipo é publicada. Seja por meio de redes sociais, notícias, vídeos, comentários e assim por diante. Nós temos nessas fontes de dados muitas informações relevantes para os algoritmos de aprendizagem.
Nós lemos e lemos muito
Os textos sempre tiveram presentes no cotidiano da humanidade. Desde da criação dos primeiros registros escritos, os textos foram fonte de informação e meio de registro histórico. Boa parte do que sabemos dos antepassados é porque está registrado de alguma forma em texto.
O fato é que ao longo de toda nossa história nós consumimos e geramos muitos textos. Se antes, esses textos estavam nos livros, hoje eles estão espalhados nos portais de notícias, em sites, em blogs e nas redes sociais. E diariamente estamos ali consumindo esse conteúdo e aprendendo com ele. A máquina também.
Na verdade a máquina já está fazendo isso muito bem. Vamos explorar alguns exemplos clássicos.
IBM Watson
O Watson é o sistema de Inteligência Artificial da IBM. Uma das coisas que ele faz bem é aprender com textos. O seus sistema de diagnóstico médico, já usado em hospitais, usa dados provenientes de diversos trabalhos científicos da medicina para inferir possíveis diagnósticos de um paciente. Mesmo que a decisão final sobre qual tratamento o paciente deve seguir seja do médico, o Watson tem um papel importante nesse processo: ele é capaz de ler e extrair informações de um artigo científico que acabou de ser publicado. Coisa que talvez um médico, dada a quantidade de tarefas, só conseguiria fazer isso meses depois.
Um caso famoso também de aplicação do Watson foi sua vitória no tradicional jogo americano Jeopardy. Segundo o wikipedia, o Jeopardy …
… É um show de perguntas e respostas (quiz) variando história, literatura, cultura e ciências. Diferentemente dos quizes tradicionais, os temas são apresentados como respostas e os concorrentes devem formular a pergunta correspondente a cada um deles.
Fonte: https://pt.wikipedia.org/wiki/Jeopardy!
Em 2011, o Watson bateu dois campeões do programa. Foram 3 dias de competições. No jogo, a informação da pergunta era passada por texto para o computador que processava as informações e relacionava com sua base de conhecimento para poder gerar uma resposta adequada. No vídeo a seguir vocês podem ver alguns momentos da competição.
Tradução Automática
Quer um outro exemplo de que as máquinas aprendem lendo? As traduções automáticas. Para quem é um pouco mais velho, deve lembrar dos primeiros tradutores online. Eles não eram tão bons. No entanto, hoje em dia a coisa é bem diferente. Ainda que existam erros, os tradutores online funcionam muito bem. Mas como a máquina aprendeu a traduzir?
O vídeo a seguir mostra como funciona o Google Translate.
De forma geral, o google translate aprende a traduzir a partir de traduções feitas por humanos passada para ele. Ele analisa o texto em uma língua, a tradução fornecida e aprende os padrões encontrados entre elas. Esses padrões são utilizados para traduzir novos textos.
O mais interessante disso é que esses padrões podem mudar a medida que novas traduções são propostas. Então, quando você corrige uma tradução, você está contribuindo para que traduções futuras sejam melhoradas. Continuem corrigindo se notarem algo de errado nas traduções.
Chatbots
Meu último exemplo é o chatbot. Talvez seja umas das tecnologias mais comentadas nos últimos anos. No entanto, ela não é tão nova assim. O primeiro chatbot é datado de 1966 e recebeu o nome de ELIZA. Apesar de usar um forma de raciocínio simples, ELIZA representa uma das primeiras iniciativas no sentido de mostrar como podemos nos comunicar com um máquina a partir de texto. Quem quiser testar a Eliza, pode conversar como ela neste site.
Hoje, muitas empresas utilizam chatbots para atendimento. Nem todos precisam de técnicas mais complexas de inteligência artificial, mas isso depende muito do propósito do chatbot. Nos últimos anos, os chatbots surgiram com uma nova roupagem e chamados de assistentes pessoais como a Siri (Apple), Google Assistant (Google) e a Cortana (Microsoft). Podemos dizer que a ELIZA é mãe destas tecnologias mais recentes.
Um exemplo que ilustra bem o poder dessa tecnologia foi aquela apresentada em 2018 pela Google. O Google Duplex é uma assistente pessoal que foi usada para marcar um horário no salão e reservar uma mesa em um restaurante. Vale a pena ver o vídeo a seguir.
Por mais impressionante que o vídeo seja, o assistente do Google não vai está amanhã marcando qualquer tipo de compromisso. A IA, nesse caso, foi treinada para casos bem específicos. No texto “Google Duplex: An AI System for Accomplishing Real-World Tasks Over the Phone”, os engenheiros do Google explicam como essa tecnologia foi desenvolvida e quais suas limitações. Basicamente, temos uma Rede Neural (mais precisamente a RNN) que foi treinada a partir de uma série de chamadas de telefone reais.
The technology is directed towards completing specific tasks, such as scheduling certain types of appointments. For such tasks, the system makes the conversational experience as natural as possible, allowing people to speak normally, like they would to another person, without having to adapt to a machine.
Fonte: https://ai.googleblog.com/2018/05/duplex-ai-system-for-natural-conversation.html
One of the key research insights was to constrain Duplex to closed domains, which are narrow enough to explore extensively. Duplex can only carry out natural conversations after being deeply trained in such domains. It cannot carry out general conversations.
Processamento de Linguagem Natural
O segredo por trás de toda essa tecnologia se chama Processamento de Linguagem Natural, campo da computação que une Inteligência Artificial e Linguística. Essa área é tão antiga quanto os chatbots, mas teve uma explosão nos últimos 10 anos por conta das chamadas redes profundas (ou Deep Learning). Os modelos deep associados ao grande volume de dados produzidos e ao aumento no poder computacional é a chave para o sucesso de ferramentas como o Google Duplex.
Quando usamos ferramentas deste tipo parece que a coisa é muito simples. Mas não é bem assim. Fazer uma máquina entender um texto é uma tarefa difícil. E isso é difícil pelo simples fato de que a linguagem humana ela é complexa por natureza. Uma única palavra não tem um único significado. São vários, que dependem do contexto no qual ela está inserida. Além disso, muitas falas são ambíguas, irônicas e sarcásticas. Até para nós humanos, em muitos casos, é difícil de entender.

Para que isso funcione, sistemas deste tipo são treinados com um grande volume de exemplos. Já pensou a dificuldade que é, por exemplo, fazer um sistema entender o que é um discurso de ódio? Precisaríamos de várias frases que indiquem o que é discurso do ódio e o que não é discurso do ódio para que a máquina conseguisse extrair os padrões relacionados a cada tipo e diferencia-los. Definitivamente não é simples, mas é um desafio de pesquisa bem interessante 😉
A imagem a seguir mostra, de forma geral, o passo a passo de um sistema deste tipo. Para cada componente do processo temos uma série de técnicas de pré-processamento, vetorização e algoritmos de machine learning.
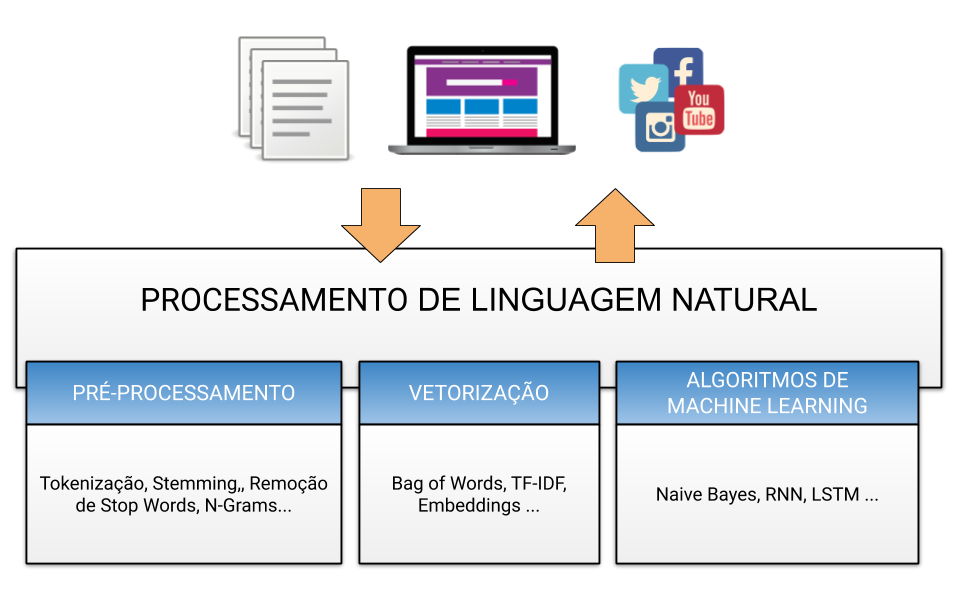
Basicamente, um conjunto de texto é coletado e sofre uma série de ações, desde pré-processamento, vetorização e aplicação dos modelos de Machine Learning. Desta forma, as informações dos textos são extraídas gerando novos textos ou informações para diversas aplicações.
Que tal explorar com mais detalhes cada uma destas técnicas? Já estou preparando um tutorial que estará disponível aqui no site em breve.
Não deixe de me seguir no Instagram @profadolfoguimaraes para ficar por dentro das postagens e assuntos relacionados à Inteligência Artificial, Machine Learning e Análise de Dados.